- Name : Machine Learning:?Regression
- Lecturer 😕Carlos Guestrin?and?Emily Fox
- Duration: 2015-12-28 ~ 2016-02-15 (6 weeks)
- Course : The 2nd(2/6) course of Machine Learning Specialization?in Coursera
- Syllabus
- Record
- Certificate
- Learning outcome
- Describe the input and output of a regression model.
- Compare and contrast bias and variance when modeling data.
- Estimate model parameters using optimization algorithms.
- Tune parameters with cross validation.
- Analyze the performance of the model.
- Describe the notion of sparsity and how LASSO leads to sparse solutions.
- Deploy methods to select between models.
- Exploit the model to form predictions.
- Build a regression model to predict prices using a housing data set.
- Implement these techniques in Python.
Syllabus ↑
Week 1 |?Simple Linear Regression
Welcome
- Welcome!
- What is the course about?
- Outlining the first half of the course
- Outlining the second half of the course
- Assumed background
Simple Linear Regression
- What is this course about?
- Regression fundamentals
- The simple linear regression model, its use, and interpretation
- An aside on optimization: one dimensional objectives
- An aside on optimization: multidimensional objectives
- Finding the least squares line
- Approach 1: Set gradient = 0
- Approach 2: Gradient descent
- Comparing the two approaches
- Discussion and summary of simple linear regression
- Influence of high leverage points
- High leverage points
- Influential observations
- Programming assignment
- Quiz: Simple Linear Regression
- Q&A
- interval, estimation, inverse estimation, unit change
- Quiz: Fitting a simple linear regression model on housing data
- A programming assignment
- 2 different models respectively by square feet and #bedrooms
Week 2 |?Multiple Regression
Multiple Regression
- Multiple features of one input
- Multiple regression intro
- Polynomial regression
- Modeling seasonality
- Where we see seasonality
- Where we see seasonality
- Regression with general features of 1 input
- Incorporating multiple inputs
- Motivating the use of multiple inputs
- Defining notation
- Regression with features of multiple inputs
- Interpreting the multiple regression fit
- Setting the stage for computing the least squares fit
- Optional reading: review of matrix algebra
- Rewriting the single observation model in vector notation
- Multiple regression by using matrices
- Rewriting the model for all observations in matrix notation
- Multiple regression by using matrices
- Computing the cost of a D-dimensional curve
- RSS of a D-dimensional curve
- Computing the least squares D-dimensional curve
- Computing the gradient of RSS
- Approach 1: closed-form solution
- Analogy by 1 dimension .
- Discussing the closed-form solution
- O(n^3): computationally intensive solution.
- There exist less intensive algorithms for the closed-form solution exist but the gradient descent is less intensive.
- Approach 2: gradient descent
- Just replace \nabla RSS(w^{(t)}) as -2 H^{T} (y - Hw )
- Feature-by-feature update
- Algorithmic summary of gradient descent approach
- Summarizing multiple regression
- A brief recap
- Quiz: Multiple Regression
- Programming assignment 1
- Reading: Exploring different multiple regression models for house price prediction
- Quiz: Exploring different multiple regression models for house price prediction
- Programming assignment 2
- Numpy tutorial
- Reading: Implementing gradient descent for multiple regression
- Quiz:?Implementing gradient descent for multiple regression
- Quiz: Multiple Regression
- Quiz: Exploring different multiple regression models for house price prediction
- Quiz: Implementing gradient descent for multiple regression
Week 3 |?Assessing Performance
Assessing Performance
- Defining how we assess performance
- 3 measures of loss and their trends with model complexity
- 3 sources of error and the bias-variance trade-off
- Irreducible error and bias
- 3 sources of error: Noise, bias, variance
- Noise is caused by neglected sources of the prediction.
- Noise: Irreducible error
- Bias(x) = f_{w(true)}(x) - f_{w(average)}(x)
- f_{w(average)}(x) = \frac{1}{N} \sum_{n=1}^{N} f_{w(trainingdata)}
- Low complexity ⇒ high bias
- High complexity ⇒ low bias
- Variance and bias-variance trade-off
- Low complexity ⇒ low variance
- High?complexity ⇒ high?variance
- Bias-variance trade-off
- Low complexity ⇒ high bias AND?low variance
- High?complexity ⇒ low bias AND high?variance
- Finding the sweet spot that complexity satisfies low bias and low variance
- MSE: Mean Squared Error
- MSE = \frac{1}{N} \sum_{n=1}^{N} \sqrt{Bias^2 + Variance}
- We cannot compute bias and variance because both contain the true function,?which cannot be computed.
- Error vs. amount of data
- For a fixed model complexity
- #(data points in training set) increases?⇒ training error increases
- #(data points in training set) increases?⇒ true error increases
- #(data points in training set) → ∞?⇒ [training error = true error]
- Irreducible error and bias
- OPTIONAL ADVANCED MATERIAL: Formally defining and deriving the 3 sources of error
- Formally defining the 3 sources of error
- Formally deriving why the 3 sources of error
- Putting the pieces together
- Training/validation/test split for model selection, fitting, and assessment
- Hypothetical implementation
- Data set = (training set) + (test set)
- Practical implementation
- Data set = (training set) + (validation set) + (test set)
- Hypothetical implementation
- A brief recap
- Quiz: Assessing Performance
- Training/validation/test split for model selection, fitting, and assessment
- Programming assignment
- Reading: Exploring the bias-variance trade-off
- Quiz:?Exploring the bias-variance trade-off
- Quiz: Assessing Performance
- Quiz: Exploring the bias-variance trade-off
- Construction of polynomial regression using the linear regression function of graphlab.
- We can construct any polynomials using the linear combination by setting features as the powers of inputs.
- If the degree of the polynomial is too large.
- train_data : validation_data : test_data = 45 : 45 : 10
- The polynomial model is fitted on train_data.
- The RSS is computed on validation_data.
- Assessment is done on test_data.
- Choose the degree of the polynomial makes?the RSS(Residual Sum of Squares) on validation_data minimal among the candidate degrees.
Week 4 |?Ridge Regression
Ridge Regression
- Characteristics of over-fit models
- Symptoms of overfitting in polynomial regression
- Overfitting demo
- Overfitting for more general multiple regression models
- The ridge objective
- Balancing fit and magnitude of coefficients
- [measure of fit] ↘ ⇒ [good fit to training data]
- [measure of magnitude of coefficient]?↘ ⇒ [not overfit]
- [total cost] = [measure of fit] + [measure of magnitude of coefficient] = [RSS] + \sum_{j=0}^{D} \left \| \mathbf{w} \right \| _{j}^{2}
- The resulting ridge objective and its extreme solutions
- Select $latex \mathbf{\hat{w}}$??to minimize the total cost C_{total}
- $latex RSS(\mathbf{\hat{w}}) + \lambda \left \| \textbf{w} \right \|_{2}^{2}$
- \lambda = 0 \Rightarrow C_{total} = RSS(\mathbf{\hat{w}})
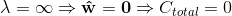
\lambda = \infty \Rightarrow \mathbf{\hat{w}} = 0?\Rightarrow C_{total} = 0
- How ridge regression balances bias and variance
- \lambda_{1} < \lambda_{2} \Rightarrow Variance_{1} < Variance_{2}
- \lambda_{1} < \lambda_{2} \Rightarrow Bias_{1} > Bias_{2}
- Ridge regression demo
- Underfit ↔ overfit
- “Leave One Out(LOO)” cross validation: the algorithm that chooses the tuning parameter, lambda \lambda
- The ridge coefficient path
- Coefficient path
- Balancing fit and magnitude of coefficients
- Optimizing the ridge objective
- Computing the gradient of the ridge objective
- <br /> RSS(\textbf{w}) + \lambda \left \| \textbf{w} \right \|_{2}^{2}<br />
- <br /> \left \| \textbf{w} \right \|_{2}^{2} = \textbf{w}^T \textbf{w}<br />
- <br /> \textbf{w} = (w_1\ w_2\ w_3\ ...\ w_D)^T<br />
- <br />
RSS(\textbf{w}) + \lambda \left \| \textbf{w} \right \|_{2}^{2}<br />
<br /> = (\textbf{y}-\textbf{Hw})^{T}(\textbf{y}-\textbf{Hw}) +\lambda \textbf{w}^T \textbf{w}<br /> - <br />
\nabla [RSS(\textbf{w}) + \lambda \left \| \textbf{w} \right \|_{2}^{2}]\\<br />
<br /> = \nabla [(\textbf{y}-\textbf{Hw})^{T}(\textbf{y}-\textbf{Hw})] +\lambda \nabla [\textbf{w}^T \textbf{w}]\\<br />
<br /> = -2 \textbf{H}^T(\textbf{y}-\textbf{Hw}) + 2 \lambda \textbf{w}<br /> - COST
<br /> \nabla cost( \textbf{w} )\\<br /> = -2 \textbf{H}^T(\textbf{y}-\textbf{Hw}) + 2 \lambda \textbf{w}\\<br /> =-2 \textbf{H}^T(\textbf{y}-\textbf{Hw}) + 2 \lambda \textbf{I} \textbf{w}<br /> - Ridge closed form solution
<br /> \nabla cost( \textbf{w} ) = 0\\<br /> \Leftrightarrow \mathbf{H}^T \mathbf{H} \mathbf{\hat{w}} + \lambda \mathbf{I} \mathbf{\hat{w}} = \mathbf{H}^T \mathbf{y}\\<br /> \Leftrightarrow (\mathbf{H}^T \mathbf{H} + \lambda \mathbf{I})\mathbf{\hat{w}} = \mathbf{H}^T \mathbf{y}\\<br /> \Leftrightarrow \mathbf{\hat{w}} = (\mathbf{H}^T \mathbf{H} + \lambda \mathbf{I})^{-1} \mathbf{H}^T \mathbf{y}<br />
- Approach 1: closed-form solution
- Discussing the closed-form solution
- Approach 2: gradient descent
- Computing the gradient of the ridge objective
- Tying up the loose ends
- Selecting tuning parameters via cross validation
- How to choose the tuning parameter \lambda
- K-fold cross validation
- How to handle the intercept
- A brief recap
- Selecting tuning parameters via cross validation
- Programming Assignment 1
- Programming Assignment 2
- Quiz: Ridge Regression
- Quiz: Observing effects of L2 penalty in polynomial regression
- Quiz: Implementing ridge regression via gradient descent
Week 5 |?Feature Selection & Lasso
Feature Selection & Lasso
- Feature selection via explicit model enumeration
- Feature selection implicitly via regularized regression
- Geometric intuition for sparsity of lasso solutions
- Setting the stage for solving the lasso
- Optimizing the lasso objective
- OPTIONAL ADVANCED MATERIAL: Deriving the lasso coordinate descent update
- Tying up loose ends
- Programming Assignment 1
- Programming Assignment 2
- Quiz: Feature Selection and Lasso
- Quiz: Using LASSO to select features
- Quiz: Implementing LASSO using coordinate descent
Week 6 |?Nearest Neighbors & Kernel Regression
Nearest Neighbors & Kernel Regression
- Motivating local fits
- Nearest neighbor regression
- k-Nearest neighbors and weighted k-nearest neighbors
- Kernel regression
- k-NN and kernel regression wrapup
- Programming Assignment
- What we’ve learned
- Summary and what’s ahead in the specialization
- Quiz: Nearest Neighbors & Kernel Regression
- Quiz: Predicting house prices using k-nearest neighbors regression
Closing Remarks
Summary
Glossary
- Models
- Fitted lines
- Regression
- Linear regression
- Simple linear regression
- Residual sum of squares [RSS]
- The least square line
- Gradient descent algorithm
- Concave functions
- Convex functions
- Hill climbing
- Hill descent
- Step size
- High leverage points
- Influential observations
- Multiple linear regression
- Polynomial regression
- Loss function
- Squared error
- Absolute error
- Training data
- Test data
- Model complexity
- fit ?a model to data
Sentences
- The small mean of training errors doesn’t guarantee the small mean of test errors.
- The smallest mean of training errors is not optimal for the mean of test errors.
- adgads \nabla RSS(w^{(t)} ???asdfasd
- ? $latex?\nabla RSS(w^{(t)} $